更多>>关于我们
 西安鲲之鹏网络信息技术有限公司从2010年开始专注于Web(网站)数据抓取领域。致力于为广大中国客户提供准确、快捷的数据采集相关服务。我们采用分布式系统架构,日采集网页数千万。我们拥有海量稳定高匿HTTP代理IP地址池,可以有效获取互联网任何公开可见信息。
西安鲲之鹏网络信息技术有限公司从2010年开始专注于Web(网站)数据抓取领域。致力于为广大中国客户提供准确、快捷的数据采集相关服务。我们采用分布式系统架构,日采集网页数千万。我们拥有海量稳定高匿HTTP代理IP地址池,可以有效获取互联网任何公开可见信息。
 您只需告诉我们您想抓取的网站是什么,您感兴趣的字段有哪些,你需要的数据是哪种格式,我们将为您做所有的工作,最后把数据(或程序)交付给你。
您只需告诉我们您想抓取的网站是什么,您感兴趣的字段有哪些,你需要的数据是哪种格式,我们将为您做所有的工作,最后把数据(或程序)交付给你。
 数据的格式可以是CSV、JSON、XML、ACCESS、SQLITE、MSSQL、MYSQL等等。
数据的格式可以是CSV、JSON、XML、ACCESS、SQLITE、MSSQL、MYSQL等等。
更多>>技术文章
更多>>官方微博
-
【经验分享】未解锁BL的手机进9008模式(Mi6X为例)
对于未解锁BL的手机,需要拆机,通过短接特定触点的方式进入9008模式。
以小米Mi6X为例:
第一步,拧掉充电口旁边的两颗螺丝。
第二步,扣开后盖,可能不太好扣,可以借助美工刀在边缘撬一下。拧掉保护条上的3个螺丝。
第三步,拔掉电池排线。看图,记着两个短接触点的位置。
第四步,用镊子短接两个触点,同时插入TypeC线,2秒左右设备管理器"端口COM"里会出现9008接口,此时松开镊子。发布时间:2024-11-27 10:13:20
-
【经验分享】已解锁BL的手机进9008模式
高通9008模式全称"Qualcomm HS-USB QDLoader 9008",它相对于recovery、fastboot和Android系统是独立的。即深刷模式,也叫EDL,号称"救砖神奇"。
对于已解锁BL的手机,进入9008相对比较简单,以小米Mi6X为例:
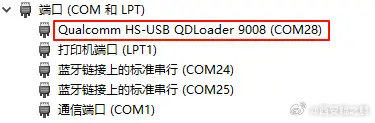
1. 先确定手机是否解锁BL了。已解锁BL的手机,刚开机的时候会有"Unlocked"字样,如附图1所示。
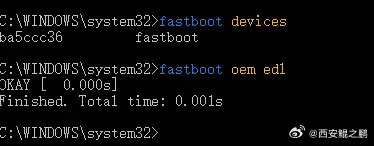
2. 长按“音量减键 + 开机键”进入fastboot。
3. 执行fastboot oem edl,即可进入9008模式,进入成功后设备管理器COM端口里可以看到"Qualcomm HS-USB QDLoader 9008"。如附图2、3所示。发布时间:2024-11-26 12:53:03
-
【经验分享】com.android.org.conscrypt.TrustManagerImpl证书固定检测绕过示例
某APP使用通用的sslunpinning脚本后仍然抓不到包:
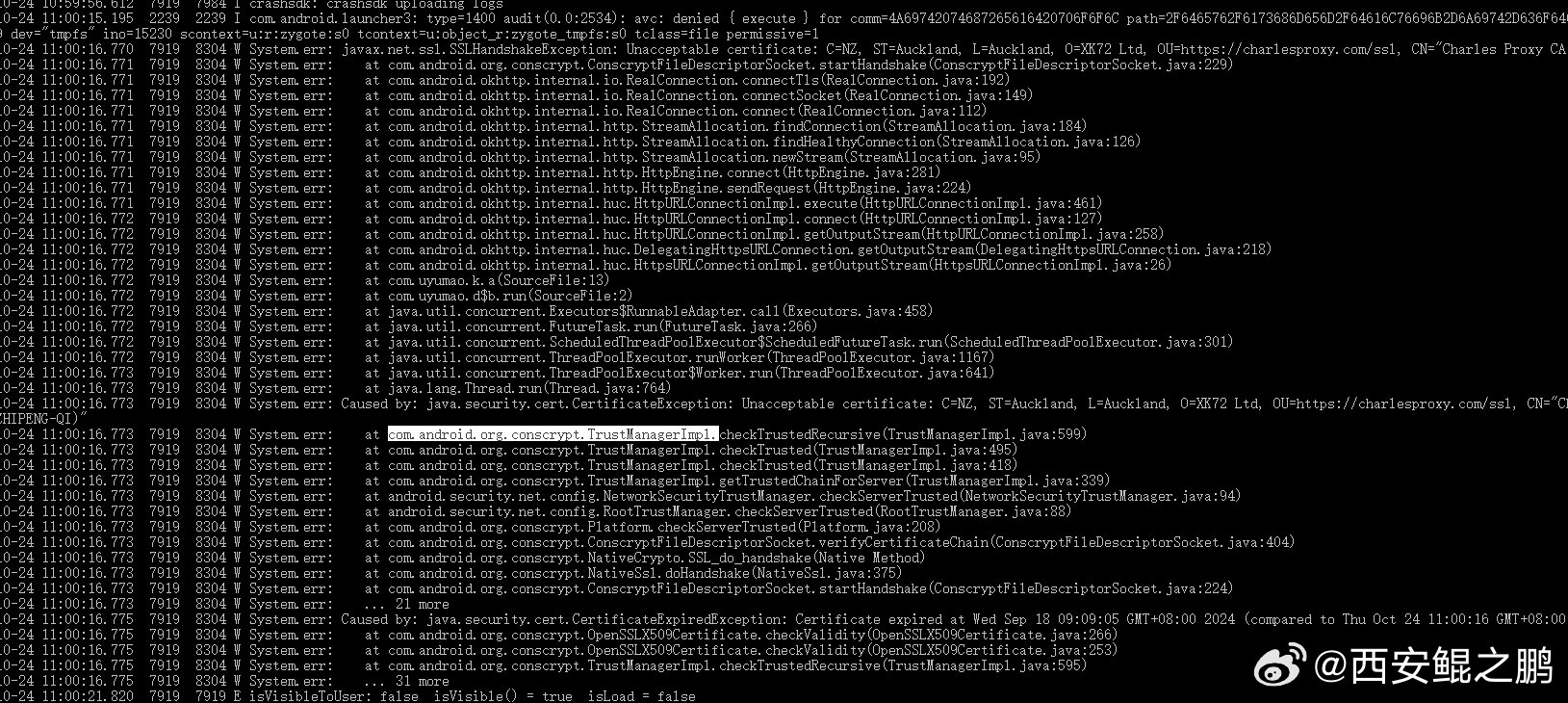
(1)分析logcat日志,发现com.android.org.conscrypt.TrustManagerImpl类相关代码抛出java.security.cert.CertificateException异常,如图1所示。
(2)hook 类com.android.org.conscrypt.TrustManagerImpl的checkTrusted和checkServerTrusted方法,返回空列表,成功抓到包。
日志线索寻找关键词:CertificateException、CertificateExpiredExceptio、SSLHandshakeException发布时间:2024-10-24 15:36:45
-
【经验分享】如何获取安卓手机上已安装APP的安装包(.apk)文件?
1. 先查看已安装APP列表,确定对应APP的包名。
adb shell pm list packages
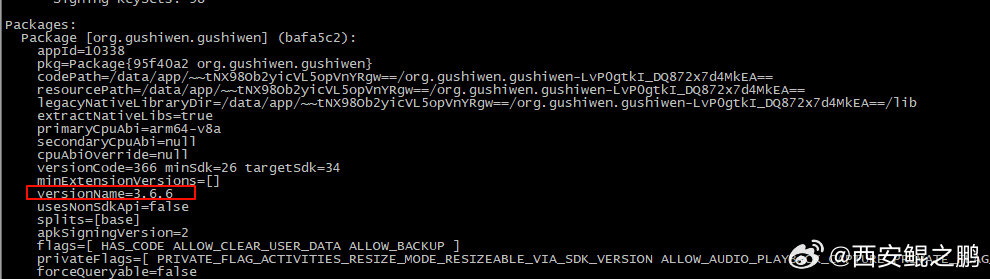
2. 假设包名为org.gushiwen.gushiwen。再根据包名查看APP的详细信息:
adb shell dumpsys package org.gushiwen.gushiwen
返回信息中的path属性,以base.apk结尾的,即就是这个APP的安装文件,如附图1所示。另外返回的信息中还有当前APP的版本(versionName属性),如附图2所示。
3. pull下来这个文件,就可以在其它设备上安装了。发布时间:2024-10-22 11:27:51
-
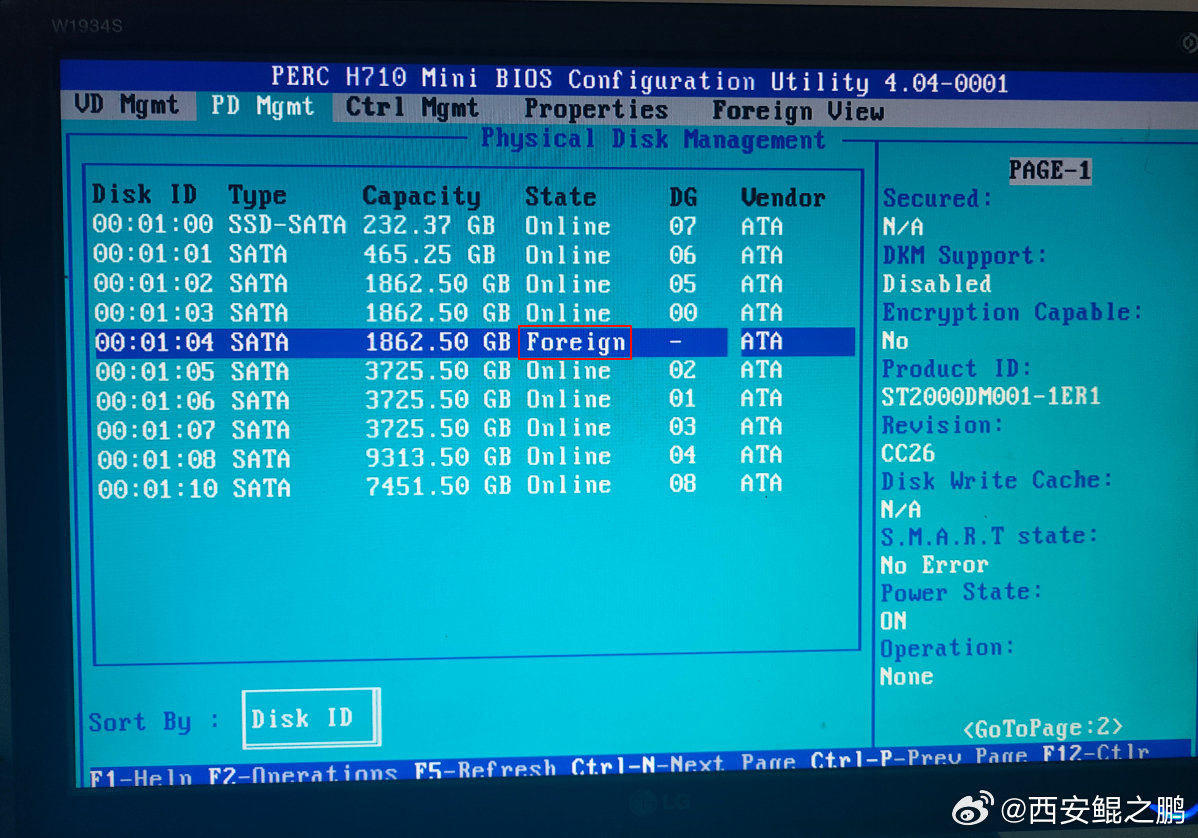
【经验分享】Dell R720意外断电重启之后丢失硬盘(硬盘状态变为Foreign)问题解决?
本来有10块盘,启动的时候显示只有9块Virtual Disk。“Ctrl + R”进入RAID设置,在“VD Mgmt”标签页下也只看到了9块Virtual Disk。在“PD Mgmt”标签页下看到是有10块物理盘,不过第5块状态变成“Foreign”了(如附图1所示)。
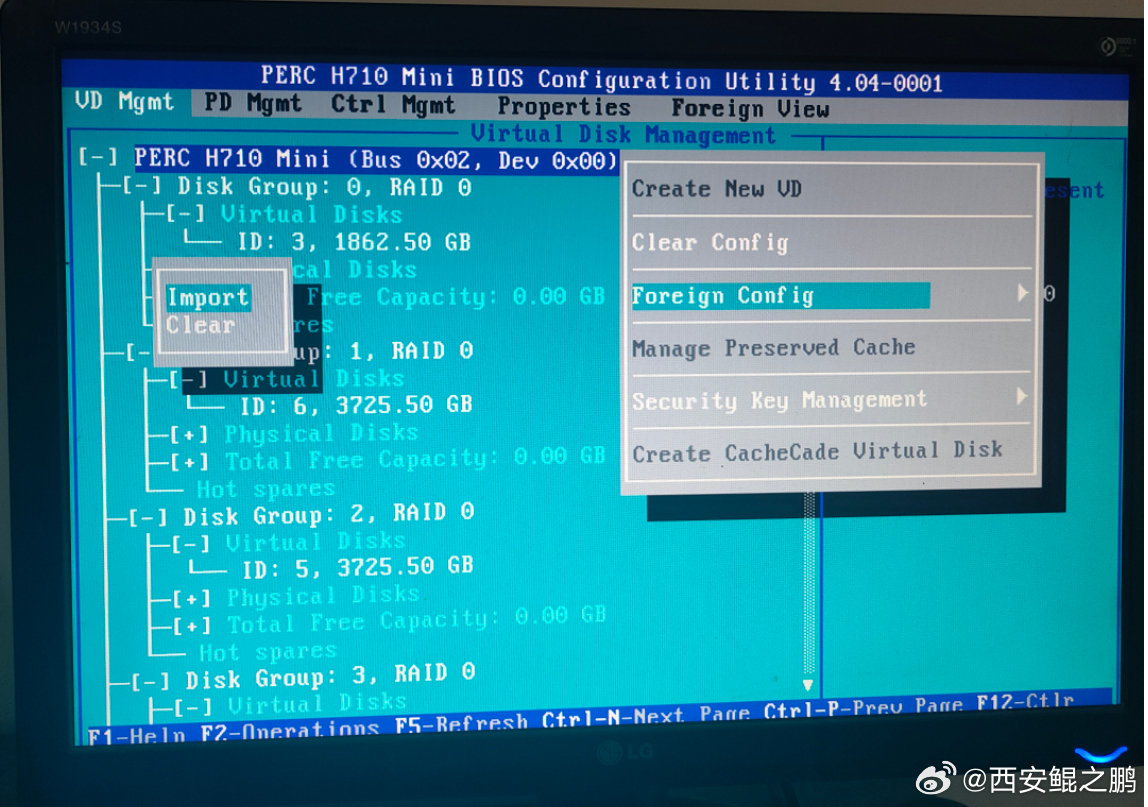
解决方法:在“VD Mgmt”标签页下,焦点切换到"PERC H710 Mini"上按F2,然后"Foreign Config",再然后"Import",操作完成(要等待几秒)之后就能看到全部盘了,如图2所示。
PS:用Ctrl + N快捷键切换菜单标签。发布时间:2024-10-18 16:35:44
-
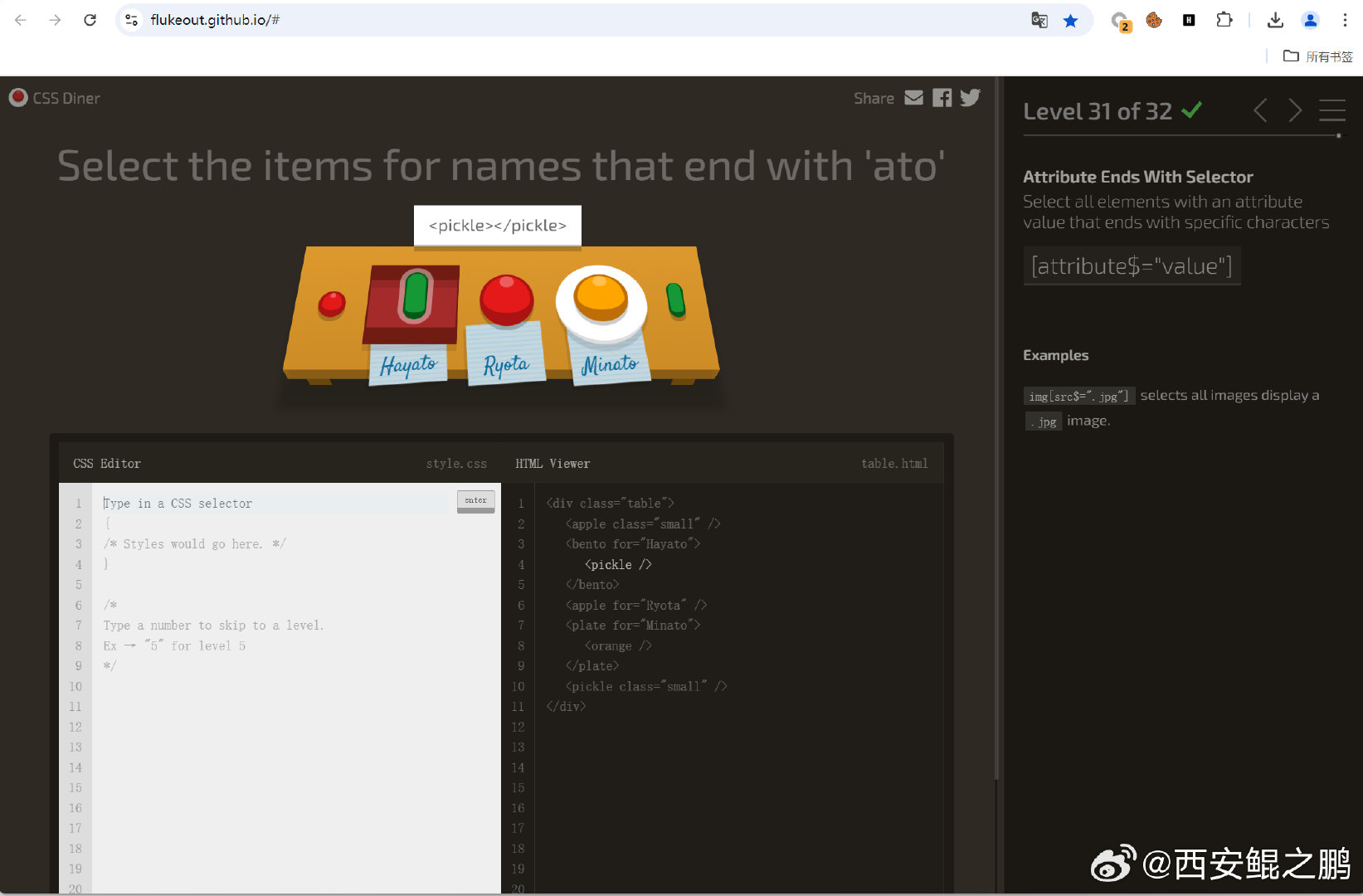
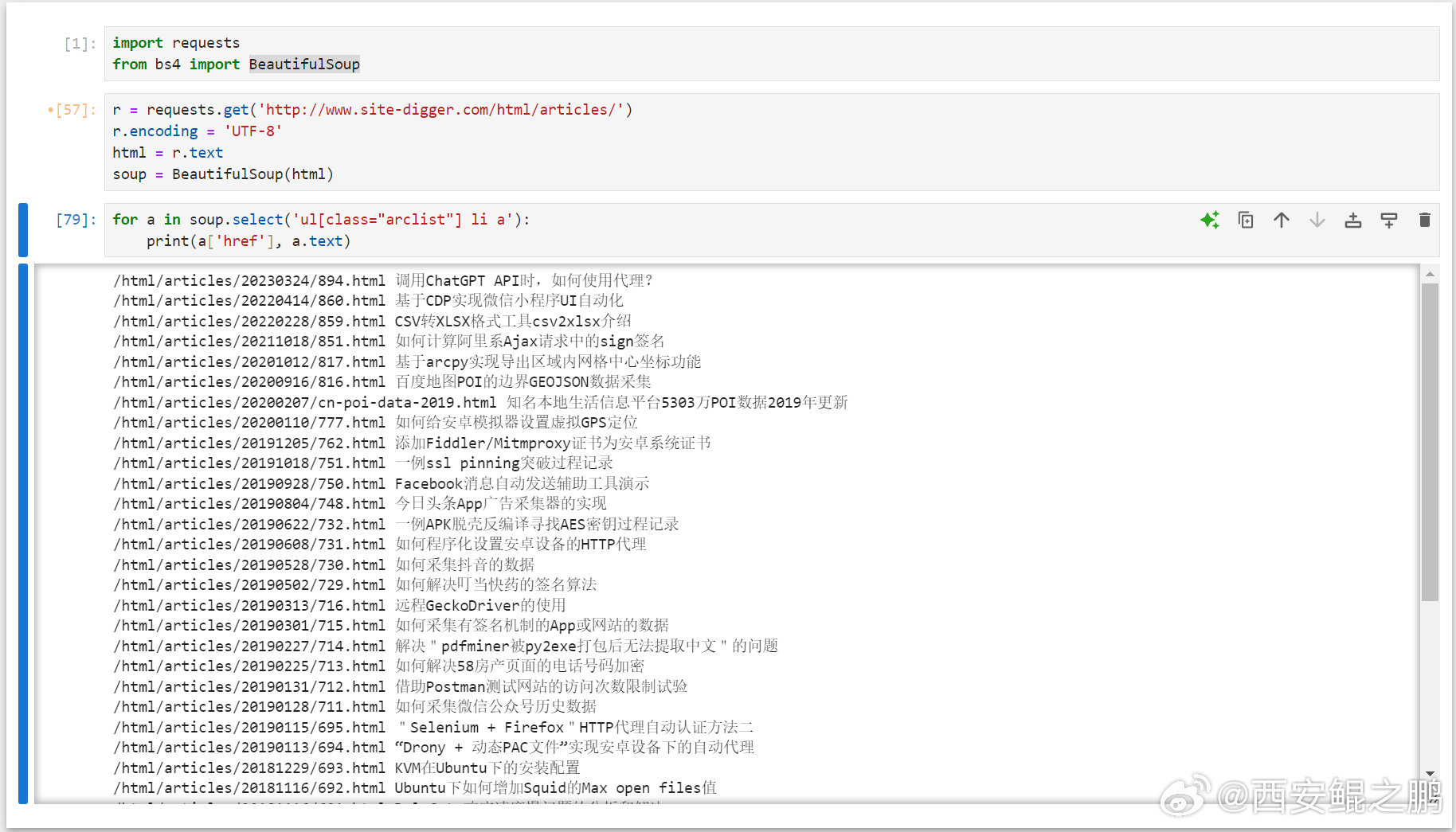
【经验分享】一个游戏闯关模式学习CSS Selector的网站"CSS Diner":https://flukeout.github.io/。
Python使用BeautifulSoup实现CSS Selector解析HTML文档的示例:
import requests
from bs4 import BeautifulSoup
r = requests.get('http://www.site-digger.com/html/articles/')
r.encoding = 'UTF-8'
html = r.text
soup = BeautifulSoup(html)
for a in soup.select('ul[class="arclist"] li a'):
print(a['href'], a.text)发布时间:2024-09-02 19:43:03
-
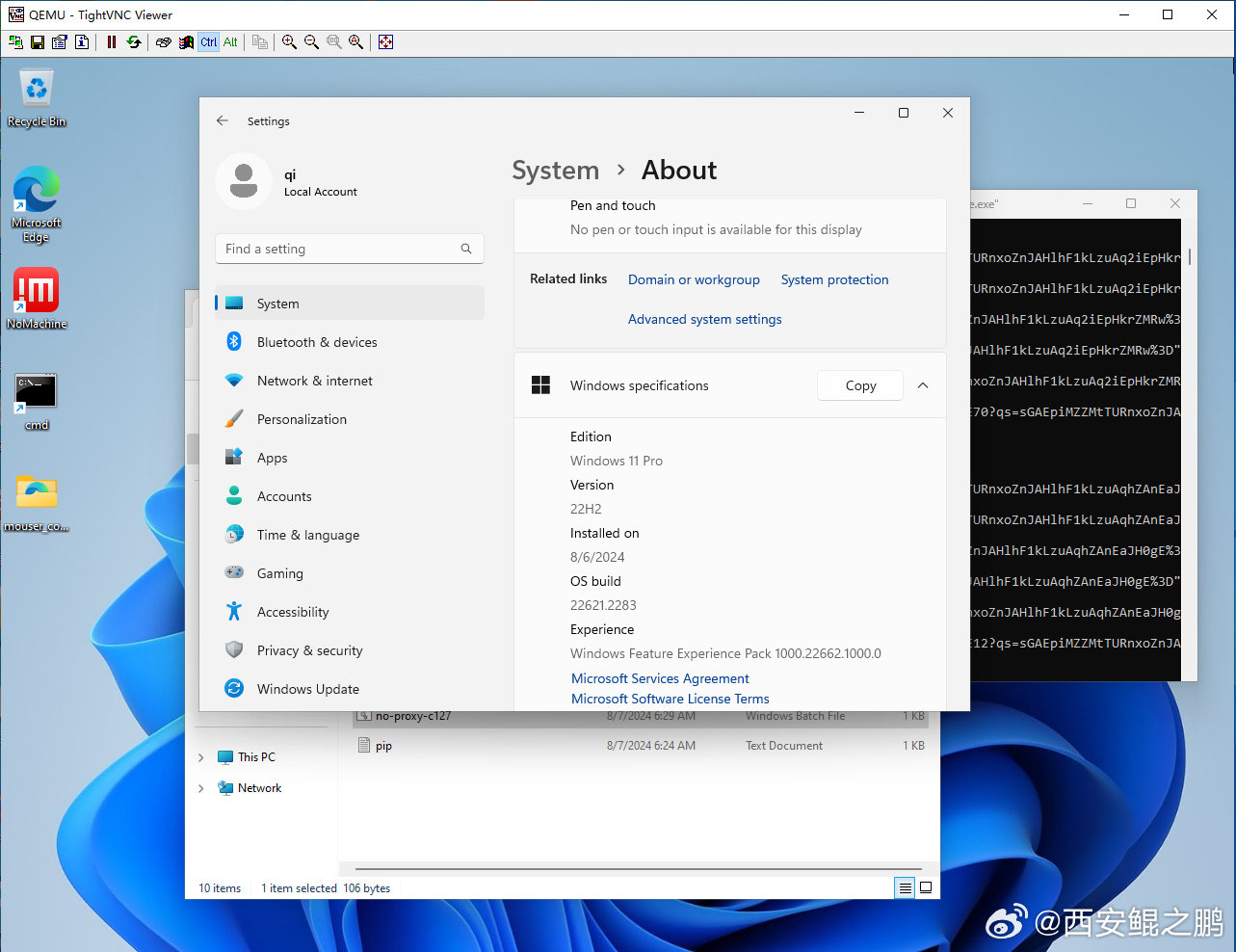
【经验分享】qemu-system-x86运行tiny11
(1) 安装qemu-system-x86,安装完成后无需重启。
sudo apt-get update
sudo apt-get install qemu qemu-utils qemu-system-x86
(2) 创建硬盘。
qemu-img create -f qcow2 tiny11.img 50G
(3) 创建虚拟机。
sudo qemu-system-x86_64 --enable-kvm -m 2G -smp 4 -boot order=dc -hda /home/qi/kvm/tiny11-1/tiny11.img -cdrom /home/qi/kvm/tiny11_23H2_x64.iso -vnc :1
(4) vnc连接 "服务器ip:5901",完成系统安装过程。设置vnc密码的方法:https://qemu-project.gitlab.io/qemu/system/vnc-security.html#with-passwords。
(5) 映射主机端口给虚拟机,使用-redir参数。如下示例,将主机的TCP/UDP4001端口映射到虚拟机的4000端口。
-redir tcp:4001::4000 -redir udp:4001::4000发布时间:2024-08-10 12:13:46
-
【经验分享】Playwright过geo.captcha-delivery.com检测
page.add_init_script('''Object.defineProperties(navigator, {webdriver:{get:()=>undefined}}); delete navigator.__proto__.webdriver;''') 发布时间:2024-07-31 10:41:18
-
【经验分享】scrcpy在网络质量欠佳环境下可以通过降低码率来提高流畅度
e.g.
scrcpy --bit-rate 1M --max-fps 5
注意:在新版本中--bit-rate参数更名为--video-bit-rate 发布时间:2024-07-03 10:11:54
-
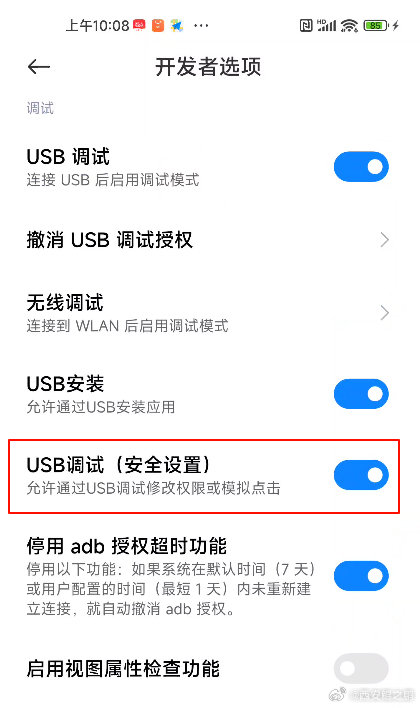
【经验分享】scrcpy在小米手机上鼠标不起作用问题的解决
在“开发者选项”中需要打开"USB调试(安全设置) - 允许通过USB调试修改权限或模拟点击"。要打开这个选项,手机需要先登录小米账号,另外手机必须要插有SIM卡。 发布时间:2024-07-03 10:09:29






发布时间:2022-02-23 来源:西安鲲之鹏官微
【经验分享】miller如何按“日期时间”类型比较(过滤)某个字段的值
如下示例:
查询统计“土地市场网土地供应结果公告数据”(csv格式)中,山东省在2010年1月1日之后的数据有多少条?
mlr --c2j --from landchina-jggg_19980101_20211231_with_coordinates_UTF8.csv filter 'strptime($合同签订日期,"%Y-%m-%d") >= strptime("2010-01-01","%Y-%m-%d") && $省=~"山东"' then count
结果如附图1所示。
参考文档:https://miller.readthedocs.io/en/latest/date-time-examples/#how-can-i-filter-by-date
mlr查询的结果和如下用pandas查询的结果是一致的(如附图2所示)。注意:pandas在read_csv()的时候,要指定parse_dates=['合同签订日期'],将该字段类型转为时间日期类型。参考文档:https://www.cnblogs.com/traditional/p/12514914.html
df.query('xingzhengqu.str.contains("广东") or province.str.contains("广东")')
如下示例:
查询统计“土地市场网土地供应结果公告数据”(csv格式)中,山东省在2010年1月1日之后的数据有多少条?
mlr --c2j --from landchina-jggg_19980101_20211231_with_coordinates_UTF8.csv filter 'strptime($合同签订日期,"%Y-%m-%d") >= strptime("2010-01-01","%Y-%m-%d") && $省=~"山东"' then count
结果如附图1所示。
参考文档:https://miller.readthedocs.io/en/latest/date-time-examples/#how-can-i-filter-by-date
mlr查询的结果和如下用pandas查询的结果是一致的(如附图2所示)。注意:pandas在read_csv()的时候,要指定parse_dates=['合同签订日期'],将该字段类型转为时间日期类型。参考文档:https://www.cnblogs.com/traditional/p/12514914.html
df.query('xingzhengqu.str.contains("广东") or province.str.contains("广东")')


特别说明:该文章为鲲鹏数据原创内容 ,您除了可以发表评论外,还可以转载到别的网站,但是请保留源地址,谢谢!!(尊重他人劳动,我们共同努力)
☹ Disqus被Qiang了,之前的评论内容都没了。如果您有爬虫相关技术方面的问题,欢迎发到我们的问答平台:http://spider.site-digger.com/