更多>>关于我们
 西安鲲之鹏网络信息技术有限公司从2010年开始专注于Web(网站)数据抓取领域。致力于为广大中国客户提供准确、快捷的数据采集相关服务。我们采用分布式系统架构,日采集网页数千万。我们拥有海量稳定高匿HTTP代理IP地址池,可以有效获取互联网任何公开可见信息。
西安鲲之鹏网络信息技术有限公司从2010年开始专注于Web(网站)数据抓取领域。致力于为广大中国客户提供准确、快捷的数据采集相关服务。我们采用分布式系统架构,日采集网页数千万。我们拥有海量稳定高匿HTTP代理IP地址池,可以有效获取互联网任何公开可见信息。
 您只需告诉我们您想抓取的网站是什么,您感兴趣的字段有哪些,你需要的数据是哪种格式,我们将为您做所有的工作,最后把数据(或程序)交付给你。
您只需告诉我们您想抓取的网站是什么,您感兴趣的字段有哪些,你需要的数据是哪种格式,我们将为您做所有的工作,最后把数据(或程序)交付给你。
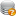 数据的格式可以是CSV、JSON、XML、ACCESS、SQLITE、MSSQL、MYSQL等等。
数据的格式可以是CSV、JSON、XML、ACCESS、SQLITE、MSSQL、MYSQL等等。
更多>>技术文章
更多>>官方微博
-
【经验分享】QEMU/KVM如何修改开机启动顺序?
virsh edit name-of-vm-instance
如下示例:
<os> <type arch='x86_64' machine='pc-i440fx-xenial'>hvm</type> <boot dev="network"></boot> <boot dev="cdrom"></boot> <boot dev="hd"></boot> <bootmenu enable='yes'/> </os>bootmenu的enable设置为yes,就可以在启动的时候按F12选择启动设备。
发布时间:2024-03-12 11:51:28
-
【经验分享】使用VNC远程连接KVM虚拟机,鼠标不同步而且偏移很大(想砸掉鼠标冲动的那种)问题解决:
(1)编辑虚拟机配置文件,例如sudo virsh edit win10_1,然后将<input type="mouse" bus="ps2" />修改为<input type="tablet" bus="usb" /> 。
(2)强制关闭虚拟机win10_1然后重启,问题解决。发布时间:2024-03-13 09:26:51
-
【经验分享】Frida里Java.choose找到某个类的实例,在调用该实例方法时出现“script should be invoke on MainThread”问题的解决:
// Assign the javascript code to a variable.
jsCode = """
// Create a method called Cheese that will be exported.
function Cheese()
{
// Perform the code from injected context.
Java.perform(function ()
{
// Variable to store the view representing the button
// to click programmatically.
var view;
// Define the Runnable type javascript wrapper.
var Runnable = Java.use("java.lang.Runnable");
// Find the MainActivity class in myApp.
Java.choose("com.example.myApp.MainActivity",
{
// Once it has been found execute the following code.
onMatch: function(instance)
{
// Get the view representing button to click.
// 2131436712 id derived from decompiling app.
view = instance.findViewById(2131436712);
// Define a new class that implements Runnable and provide
// the implementation of the run() method which, will
// execute from the Main thread.
const MyRunnable = Java.registerClass({
name:'com.example.MyRunnable',
implements: [Runnable],
methods: {
// run executes button click.
run(){
instance.onClick(view);
},
}
});
// Create an instance of the class just created.
var MyGuiUpdate = MyRunnable .$new();
// Schedule the run method in MyGuiUpdate to
// execute on the UI thread.
instance.runOnUiThread(MyGuiUpdate );
},
onComplete:function(){}
});
解决方法来源:https://stackoverflow.com/questions/65790594/calling-an-api-to-modify-an-apps-gui-from-non-main-thread-in-frida发布时间:2024-02-23 13:00:33
-
【经验分享】Frida script中如何给Java的Long类型变量赋值?
例如,某Java类中有如下Long类型变量定义:
/* renamed from: e */
public Long f90137e;
尝试修改e的值,依次做如下测试:
(1)classObj.e.value = 1978705204; 会报"Error: Expected value compatible with java.lang.Long"错误。
(2)classObj.e.value = Java.use('java.lang.Long').parseLong.overload('java.lang.String').call(Java.use('java.lang.Long'), "1978705204");依然会报上述错误。
(3)这个方法可以成功赋值:classObj.e.value = Java.use('java.lang.Long').$new(1978705204);发布时间:2024-02-21 21:45:47
-
【经验分享】miller使用filter查询条件,当遇到字段含有空格或者其它特殊字符时怎么处理?如下示例中某个字段含有点号,直接查询会报错。解决方法如下:
示例:mlr --icsv --oxtab --from mouser_products_202312.csv filter '${Mfr.}=~"TDK" || ${Brand}=~"TDK"' then count
使用Pandas时,也有类似问题,解决方法:
df[df['Brand'].str.contains("TDK")|df['Mfr.'].str.contains("TDK")]
另外,Stackoverflow(https://stackoverflow.com/questions/50697536/pandas-query-function-not-working-with-spaces-in-column-names)上有人说可以用`字段`将字段包裹起来,例如:a.query('`a b` == 5') ,但是需要Pandas是0.25版本,我机器上是0.24.2,测试没有效果。发布时间:2024-02-21 19:01:04
-
【经验分享】今天本地windows系统adb shell突然报错"error: unknown host service",尝试"adb kill-server"、甚至重启PC和手机均不起作用。后来网上查了下,说是PC端adb的后台服务进程的5037端口被其它程序占用了。
解决方法:使用netstat -ano找到并关闭占有者进程,问题解决。 发布时间:2024-02-21 18:55:05
-
【经验分享】PPPOE认证返回“User Locked”,可能是因为MAC被拉黑了,换一个就好了。
发布时间:2024-01-16 13:00:17
-
【经验分享】Linux如何限制一个命令的运行时长?可以使用timeout命令。
例如,限制ping最多运行10秒,可以这样:
timeout 10s ping www.baidu.com 发布时间:2024-01-12 12:11:50
-
【经验分享】Playwright库使用context.route()/page.route()过滤HTTP(S)请求时发现有Ajax漏包的情况。查官方文档,发现有云:
browser_context.route() will not intercept requests intercepted by Service Worker. See this issue. We recommend disabling Service Workers when using request interception by setting browser.new_context.service_workers to 'block'.
尝试:
context = browser.new_context(service_workers='block')
问题解决。
参考1:https://playwright.dev/python/docs/api/class-browsercontext#browser-context-route
参考2:https://github.com/microsoft/playwright/issues/15684发布时间:2024-01-10 11:56:20
-
【经验分享】Python fontTools 获取字体文件的字形名称列表,遇到"smile", "question", "space"等AGL名称,如何将其转为Unicode代码?
>>>import fontTools
>>>hex(fontTools.agl.AGL2UV['smileface'])
'0x263a'
参考:https://fonttools.readthedocs.io/en/latest/_modules/fontTools/agl.html 发布时间:2023-10-12 10:58:26




折叠什么是Web数据抓取?
Web数据抓取(Web scraping,也叫Web数据采集)指的是批量、快速从网站上提取信息的一种计算机软件技术。Web数据抓取程序模拟浏览器的行为,能将可以在浏览器上显示的任何数据提取出来,因此也称为屏幕抓取(Screen scraping)。Web数据抓取的最终目的是将非结构化的信息从大量的网页中抽取出来以结构化的方式存储(CSV、JSON、XML、ACCESS、SQLITE、MSSQL、MYSQL等等)。
折叠Web数据抓取有什么用处?
任何业务运营成功的基础是拥有大量的目标用户和专业数据,谁能把握用户,谁就能占得先机。Web数据抓取服务可以帮您迅速获得大量的目标用户和专业数据,使您在降低运营成本的同时,迅速抢占先机,占领制高点。 许多的客户都直接从我们的服务或者定制软件中获益。
许多的客户都直接从我们的服务中获益。
您能把我们的服务用于以下方面:
- 产生您的潜在客户列表
- 从您的竞争对手中收集您感兴趣的信息
- 抓取新兴业务数据
- 建立您自己的产品目录
- 整合行业信息,辅助经营决策
- 建立垂直搜索引擎
- Web系统自动化
- 舆情监控等等
折叠Web数据抓取有什么好处?
简单: 您不需要使用任何的软件,只需要告诉我们您的目标网站和你感兴趣的内容。
弹性: 您能从任何的网站上获取任何数据,特别是动态网站上的数据。
快捷: 对于一个需要20个人工作日完成的工作,我们能在数小时内完成。
定制: 针对不同的目标网站定制采集程序,灵活应对不同的异构网站。
精确: 抽取结果的每一列都是您所需要的,不多也不少。
低价: 您可以节省无法以金钱来计量的时间和精力,以及数倍于所付费用的人工和设备投入!
折叠Web数据抓取是否合法?
Web数据抓取程序的原理类似于搜索引擎的爬虫。
1、信息是不具有版权的,任何人都可以使用他人已公开的信息;
2、信息的组织和编撰具有版权,如果你完全使用对方网站上信息的编排方式和编排文字的话,可能存在版权侵权的行为。