更多>>关于我们
 西安鲲之鹏网络信息技术有限公司从2010年开始专注于Web(网站)数据抓取领域。致力于为广大中国客户提供准确、快捷的数据采集相关服务。我们采用分布式系统架构,日采集网页数千万。我们拥有海量稳定高匿HTTP代理IP地址池,可以有效获取互联网任何公开可见信息。
西安鲲之鹏网络信息技术有限公司从2010年开始专注于Web(网站)数据抓取领域。致力于为广大中国客户提供准确、快捷的数据采集相关服务。我们采用分布式系统架构,日采集网页数千万。我们拥有海量稳定高匿HTTP代理IP地址池,可以有效获取互联网任何公开可见信息。
 您只需告诉我们您想抓取的网站是什么,您感兴趣的字段有哪些,你需要的数据是哪种格式,我们将为您做所有的工作,最后把数据(或程序)交付给你。
您只需告诉我们您想抓取的网站是什么,您感兴趣的字段有哪些,你需要的数据是哪种格式,我们将为您做所有的工作,最后把数据(或程序)交付给你。
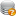 数据的格式可以是CSV、JSON、XML、ACCESS、SQLITE、MSSQL、MYSQL等等。
数据的格式可以是CSV、JSON、XML、ACCESS、SQLITE、MSSQL、MYSQL等等。
更多>>技术文章
更多>>官方微博
-
【经验分享】未解锁BL的手机进9008模式(Mi6X为例)
对于未解锁BL的手机,需要拆机,通过短接特定触点的方式进入9008模式。
以小米Mi6X为例:
第一步,拧掉充电口旁边的两颗螺丝。
第二步,扣开后盖,可能不太好扣,可以借助美工刀在边缘撬一下。拧掉保护条上的3个螺丝。
第三步,拔掉电池排线。看图,记着两个短接触点的位置。
第四步,用镊子短接两个触点,同时插入TypeC线,2秒左右设备管理器"端口COM"里会出现9008接口,此时松开镊子。发布时间:2024-11-27 10:13:20
-
【经验分享】已解锁BL的手机进9008模式
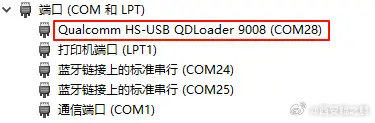
高通9008模式全称"Qualcomm HS-USB QDLoader 9008",它相对于recovery、fastboot和Android系统是独立的。即深刷模式,也叫EDL,号称"救砖神奇"。
对于已解锁BL的手机,进入9008相对比较简单,以小米Mi6X为例:
1. 先确定手机是否解锁BL了。已解锁BL的手机,刚开机的时候会有"Unlocked"字样,如附图1所示。
2. 长按“音量减键 + 开机键”进入fastboot。
3. 执行fastboot oem edl,即可进入9008模式,进入成功后设备管理器COM端口里可以看到"Qualcomm HS-USB QDLoader 9008"。如附图2、3所示。发布时间:2024-11-26 12:53:03
-
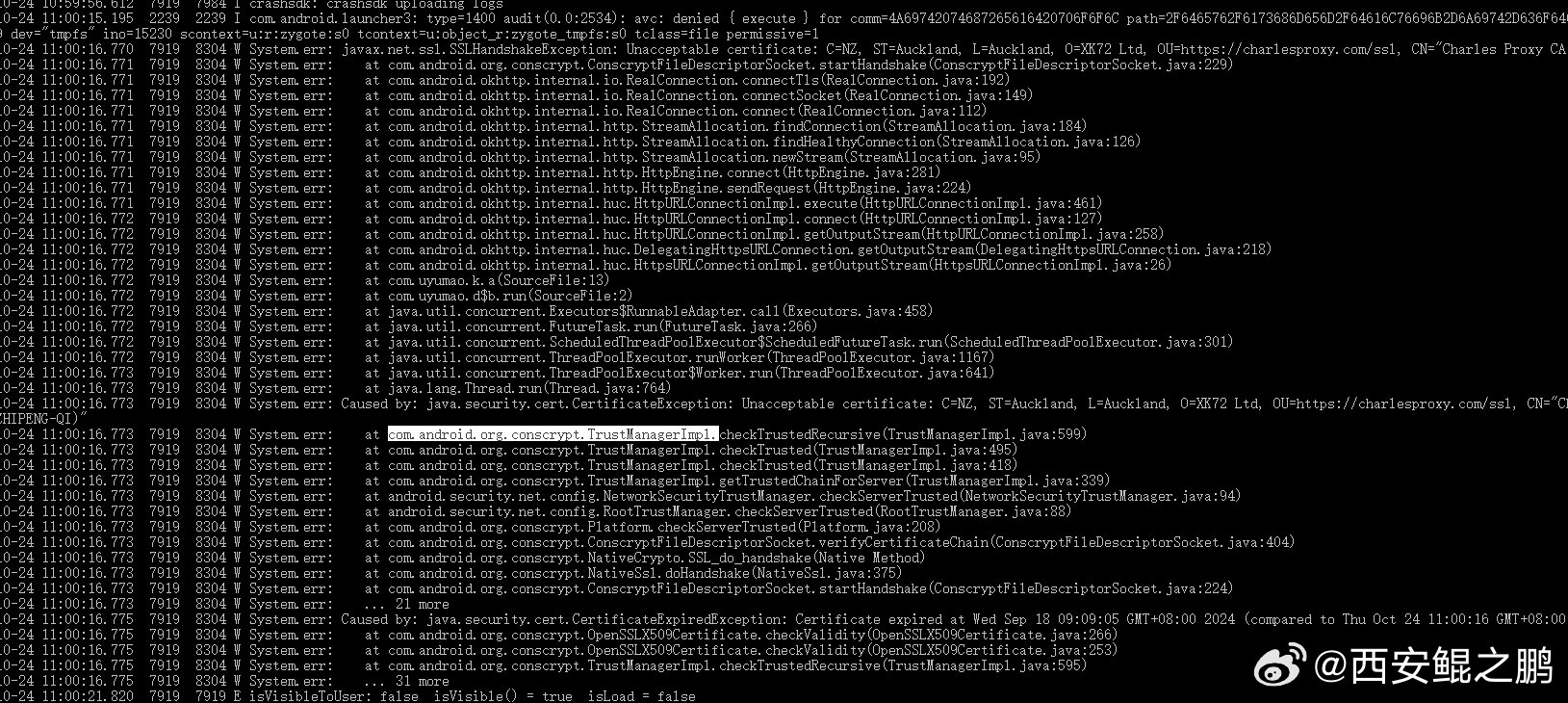
【经验分享】com.android.org.conscrypt.TrustManagerImpl证书固定检测绕过示例
某APP使用通用的sslunpinning脚本后仍然抓不到包:
(1)分析logcat日志,发现com.android.org.conscrypt.TrustManagerImpl类相关代码抛出java.security.cert.CertificateException异常,如图1所示。
(2)hook 类com.android.org.conscrypt.TrustManagerImpl的checkTrusted和checkServerTrusted方法,返回空列表,成功抓到包。
日志线索寻找关键词:CertificateException、CertificateExpiredExceptio、SSLHandshakeException发布时间:2024-10-24 15:36:45
-
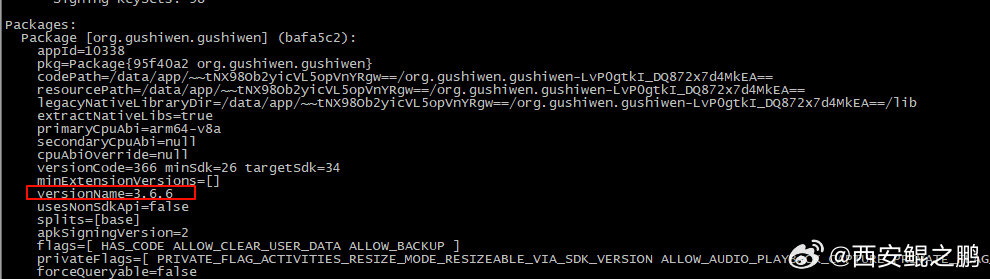
【经验分享】如何获取安卓手机上已安装APP的安装包(.apk)文件?
1. 先查看已安装APP列表,确定对应APP的包名。
adb shell pm list packages
2. 假设包名为org.gushiwen.gushiwen。再根据包名查看APP的详细信息:
adb shell dumpsys package org.gushiwen.gushiwen
返回信息中的path属性,以base.apk结尾的,即就是这个APP的安装文件,如附图1所示。另外返回的信息中还有当前APP的版本(versionName属性),如附图2所示。
3. pull下来这个文件,就可以在其它设备上安装了。发布时间:2024-10-22 11:27:51
-
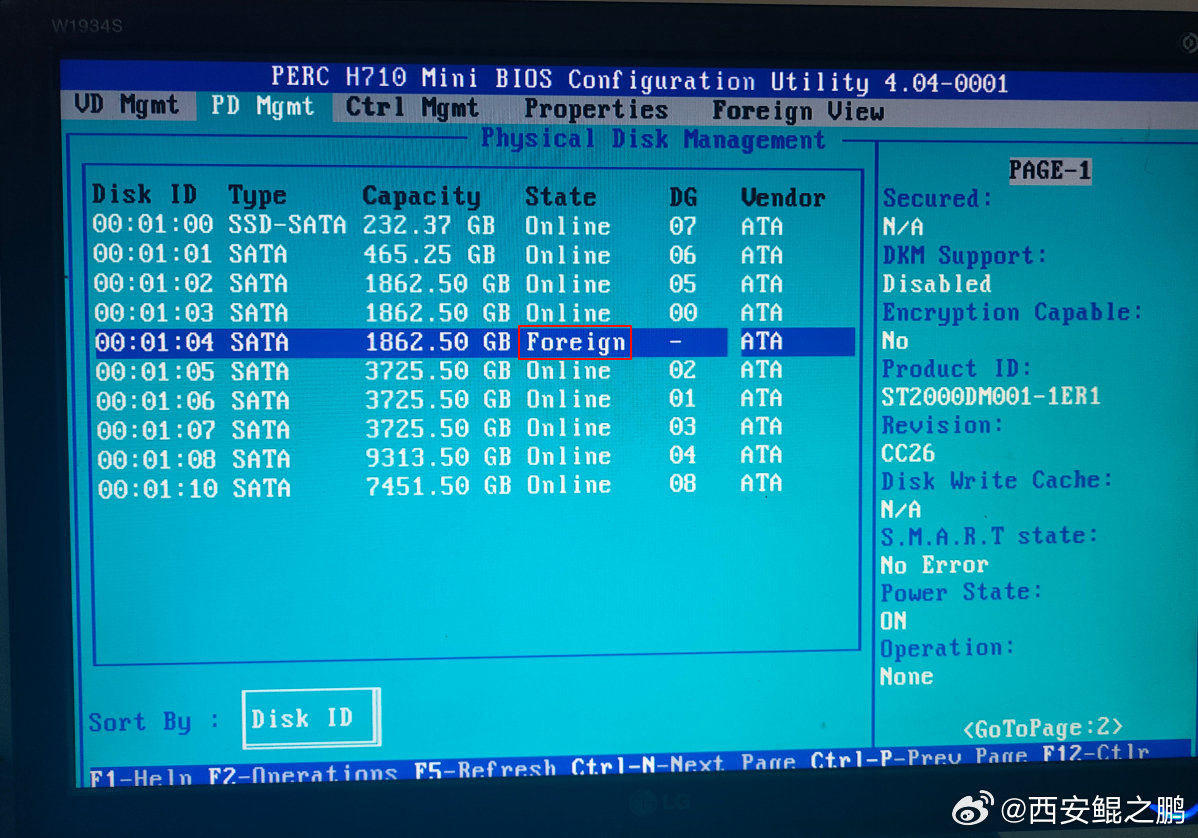
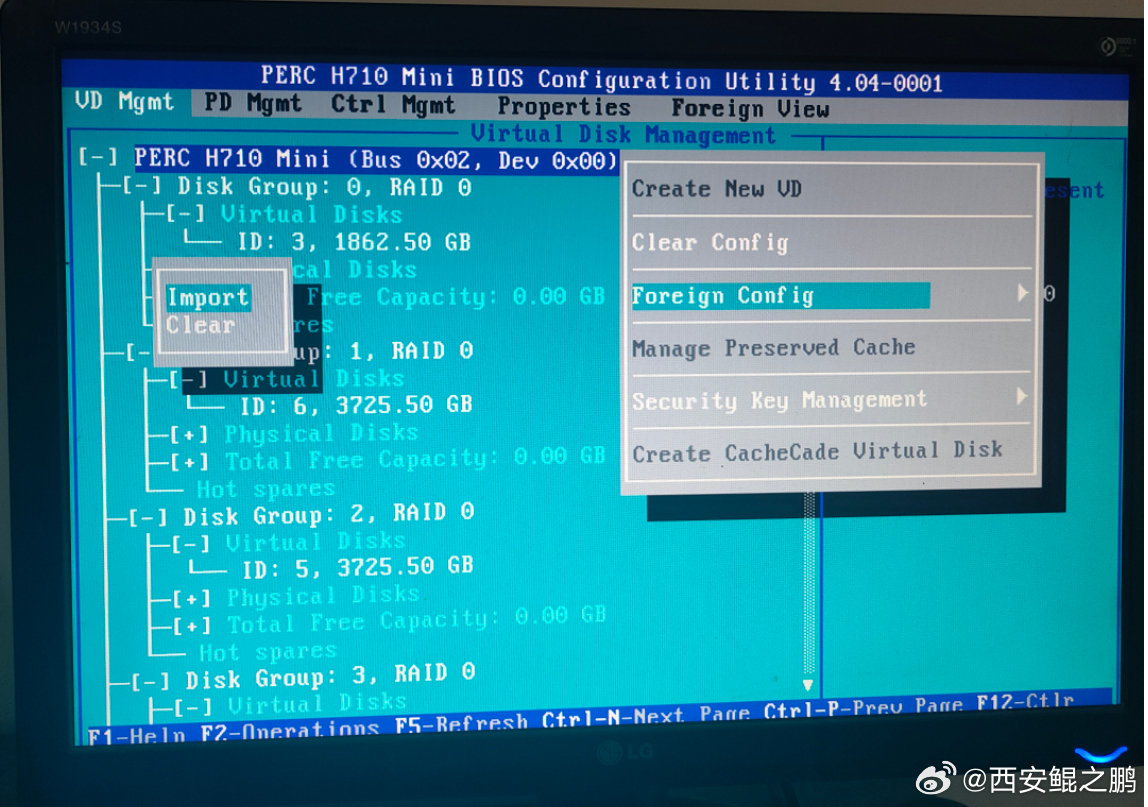
【经验分享】Dell R720意外断电重启之后丢失硬盘(硬盘状态变为Foreign)问题解决?
本来有10块盘,启动的时候显示只有9块Virtual Disk。“Ctrl + R”进入RAID设置,在“VD Mgmt”标签页下也只看到了9块Virtual Disk。在“PD Mgmt”标签页下看到是有10块物理盘,不过第5块状态变成“Foreign”了(如附图1所示)。
解决方法:在“VD Mgmt”标签页下,焦点切换到"PERC H710 Mini"上按F2,然后"Foreign Config",再然后"Import",操作完成(要等待几秒)之后就能看到全部盘了,如图2所示。
PS:用Ctrl + N快捷键切换菜单标签。发布时间:2024-10-18 16:35:44
-
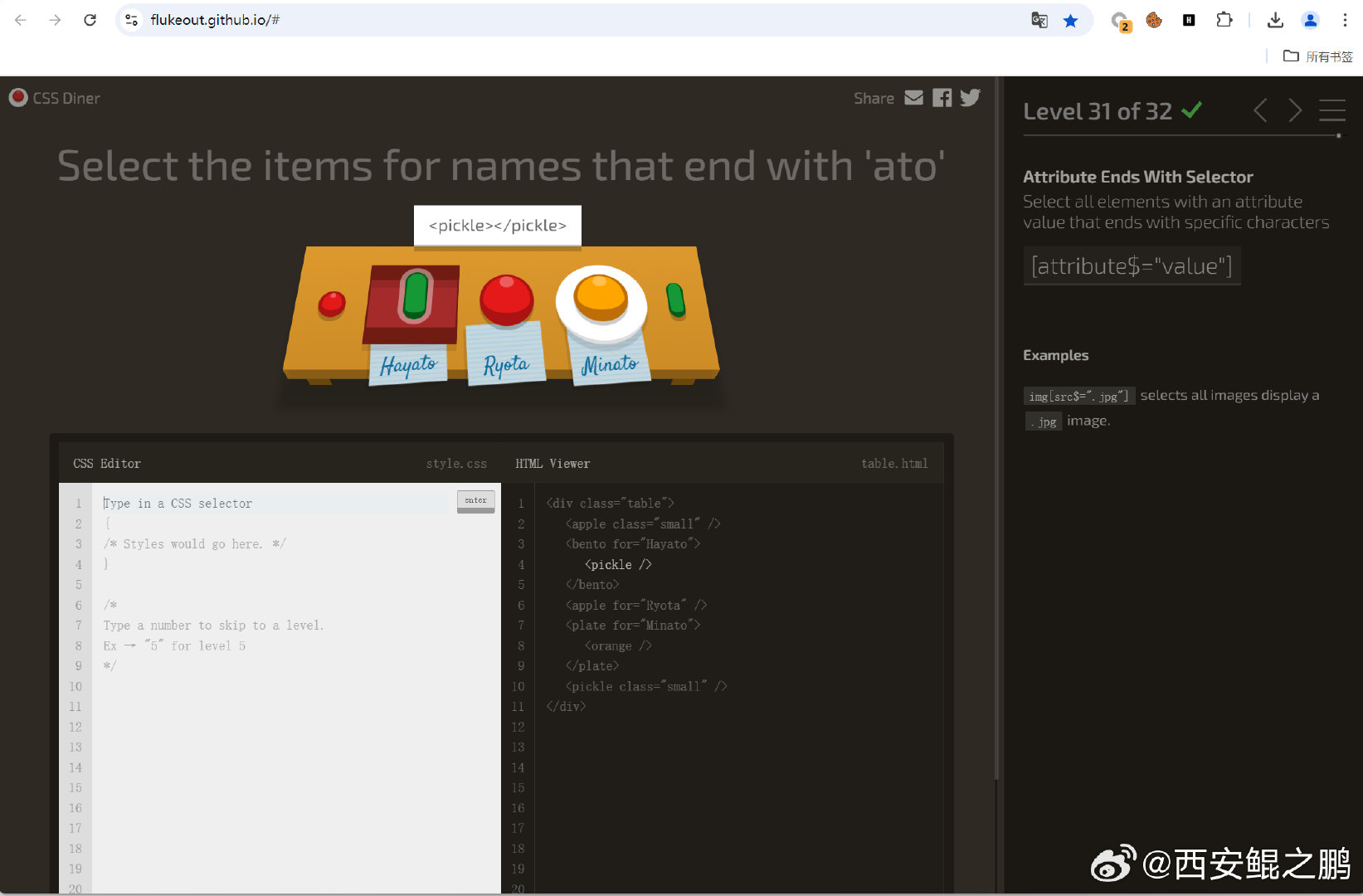
【经验分享】一个游戏闯关模式学习CSS Selector的网站"CSS Diner":https://flukeout.github.io/。
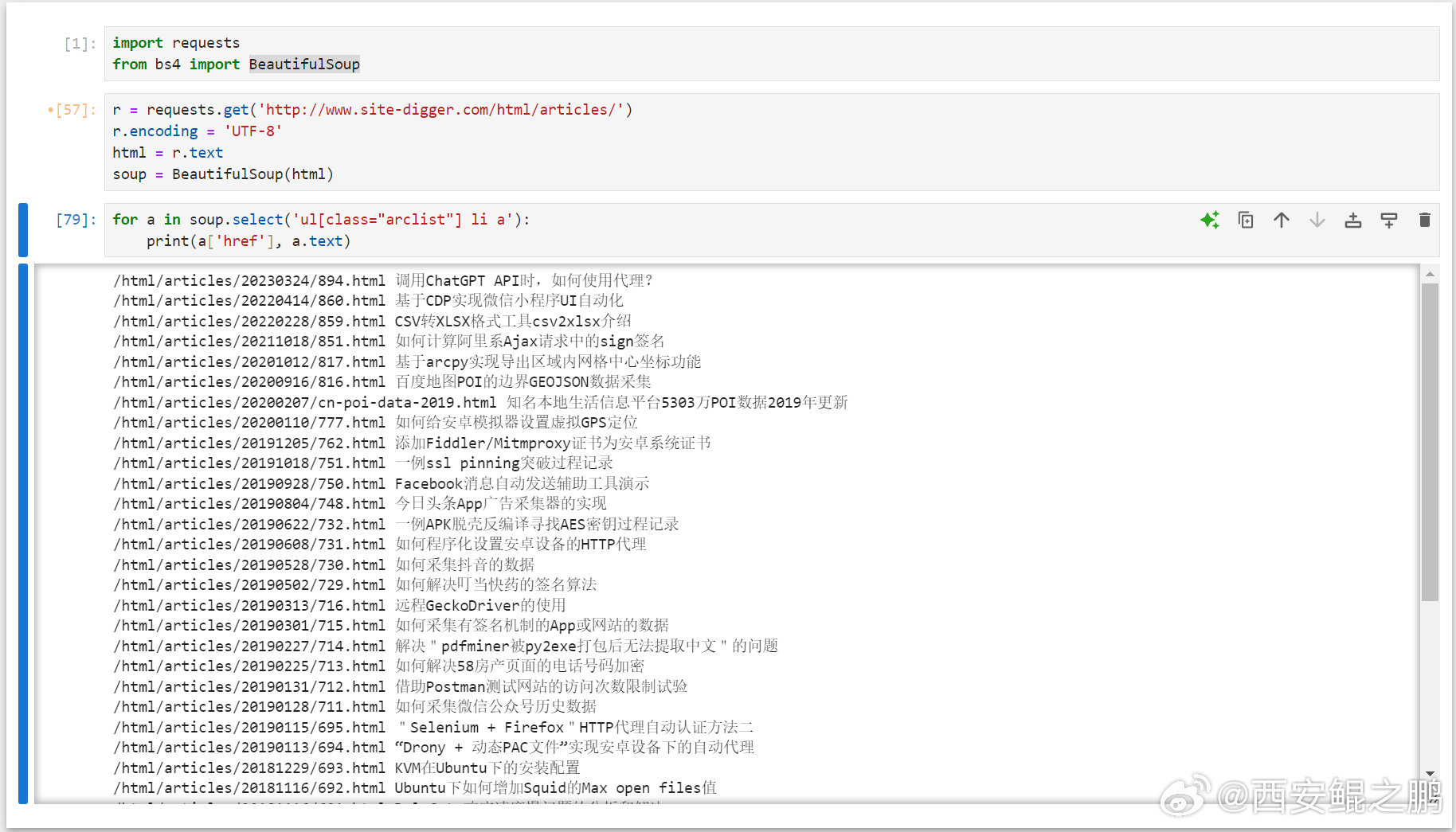
Python使用BeautifulSoup实现CSS Selector解析HTML文档的示例:
import requests
from bs4 import BeautifulSoup
r = requests.get('http://www.site-digger.com/html/articles/')
r.encoding = 'UTF-8'
html = r.text
soup = BeautifulSoup(html)
for a in soup.select('ul[class="arclist"] li a'):
print(a['href'], a.text)发布时间:2024-09-02 19:43:03
-
【经验分享】qemu-system-x86运行tiny11
(1) 安装qemu-system-x86,安装完成后无需重启。
sudo apt-get update
sudo apt-get install qemu qemu-utils qemu-system-x86
(2) 创建硬盘。
qemu-img create -f qcow2 tiny11.img 50G
(3) 创建虚拟机。
sudo qemu-system-x86_64 --enable-kvm -m 2G -smp 4 -boot order=dc -hda /home/qi/kvm/tiny11-1/tiny11.img -cdrom /home/qi/kvm/tiny11_23H2_x64.iso -vnc :1
(4) vnc连接 "服务器ip:5901",完成系统安装过程。设置vnc密码的方法:https://qemu-project.gitlab.io/qemu/system/vnc-security.html#with-passwords。
(5) 映射主机端口给虚拟机,使用-redir参数。如下示例,将主机的TCP/UDP4001端口映射到虚拟机的4000端口。
-redir tcp:4001::4000 -redir udp:4001::4000发布时间:2024-08-10 12:13:46
-
【经验分享】Playwright过geo.captcha-delivery.com检测
page.add_init_script('''Object.defineProperties(navigator, {webdriver:{get:()=>undefined}}); delete navigator.__proto__.webdriver;''') 发布时间:2024-07-31 10:41:18
-
【经验分享】scrcpy在网络质量欠佳环境下可以通过降低码率来提高流畅度
e.g.
scrcpy --bit-rate 1M --max-fps 5
注意:在新版本中--bit-rate参数更名为--video-bit-rate 发布时间:2024-07-03 10:11:54
-
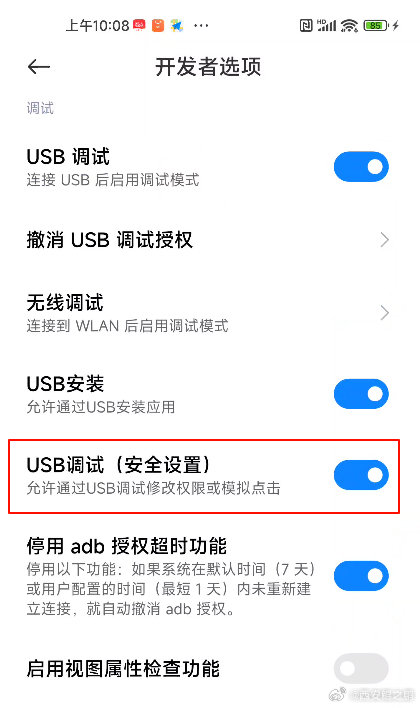
【经验分享】scrcpy在小米手机上鼠标不起作用问题的解决
在“开发者选项”中需要打开"USB调试(安全设置) - 允许通过USB调试修改权限或模拟点击"。要打开这个选项,手机需要先登录小米账号,另外手机必须要插有SIM卡。 发布时间:2024-07-03 10:09:29





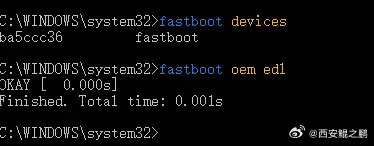

熟悉Firefox的同学都知道,Firefox在配置HTTP代理时无法设置用户名和密码。而收费的HTTP代理大多都是需要进行用户名和密码认证的(有的也支持IP白名单,但前提是你的IP需要固定不变)。这就使得使用Selenium + Firefox进行自动化操作非常不方便,因为每次启动一个新的浏览器实例就会弹出一个授权验证窗口,被要求输入用户名和密码(如下图所示),打断了自动化操作流程。

另外,Firefox也没有提供设置用户名密码的命令行参数(PS:phantomjs就有--proxy-auth这样的参数)。难道真的没有解决方法了?
鲲之鹏的技术人员通过研究终于找到了一个有效并且稳定的解决方案:
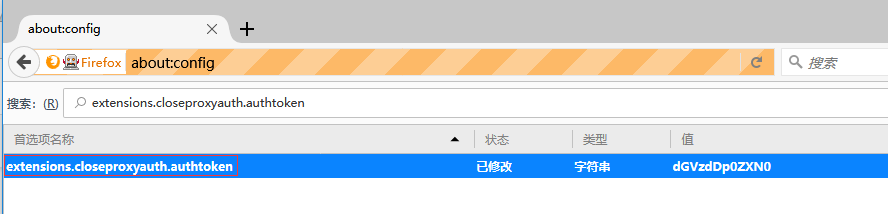
先介绍一个重要的角色,它的主页是https://addons.mozilla.org/en-US/firefox/addon/close-proxy-authentication/。close-proxy-authentication实现了自动完成代理用户名密码认证(Proxy Authentication)的功能,它提供了一个extensions.closeproxyauth.authtoken参数用来设置代理的用户名和密码,其值为经过base64编码后的用户名密码对(如下图所示)。close-proxy-authentication会使用该值构造出"Proxy-Authorization: Basic dGVzdDp0ZXN0"头发给代理服务器,以通过认证,这就是它的工作原理。
我们就是要借助这个插件在Selenium + Firefox时自动完成HTTP代理认证,流程是这样的:
(1)通过Firefox配置选项动态添加close-proxy-authentication这个插件(默认不加载任何插件);
(2)通过配置选项设置HTTP代理的IP和端口参数;
(3)设置extensions.closeproxyauth.authtoken的值为base64encode("用户名:密码");
(4)后续访问网站的时候close-proxy-authentication插件将自动完成代理的授权验证过程,不会再弹出认证窗口;
下面是完整的测试代码:
# coding: utf-8
# selenium_firefox_proxy_auto_auth.py
import sys
import time
from base64 import b64encode
from selenium import webdriver
# close-proxy-authentication插件的路径
# https://addons.mozilla.org/en-US/firefox/addon/close-proxy-authentication/
PROXY_HELPER_DIR = 'close_proxy_authentication-1.1.xpi'
def test():
# HTTP(S)类型代理参数
proxy_host = '221.229.204.91'
proxy_port = 8888
proxy_username = '******'
proxy_password = '******'
fp = webdriver.FirefoxProfile()
# 添加代理认证插件
fp.add_extension(PROXY_HELPER_DIR)
# 设置代理参数
fp.set_preference('network.proxy.type', 1)
fp.set_preference('network.proxy.http', proxy_host)
fp.set_preference('network.proxy.http_port', proxy_port)
fp.set_preference('network.proxy.ssl', proxy_host)
fp.set_preference('network.proxy.ssl_port', proxy_port)
# 给close-proxy-authentication插件设置authtoken(即代理认证的用户名和密码)
credentials = '{}:{}'.format(proxy_username, proxy_password)
credentials = b64encode(credentials)
fp.set_preference('extensions.closeproxyauth.authtoken', credentials)
firefox = webdriver.Firefox(firefox_profile=fp)
# 访问http://httpbin.org/ip回显当前IP
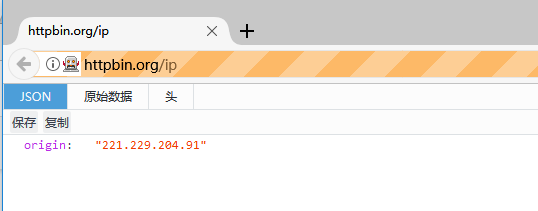
firefox.get('http://httpbin.org/ip')
time.sleep(1000)
if __name__ == '__main__':
test()
测试环境:
Firefox V53.0 geckodriver v0.18.0 selenium V3.8.0 close-proxy-authentication V1.1
上述环境涉及文件打包下载地址:http://pan.webscraping.cn:8000/index.php/s/PMDjc77gbCFJzpO
需要特别注意的是:
(1)close-proxy-authentication的最新版本目前是V1.1,它并不兼容最新版的Firefox,鲲之鹏的技术人员测试发现Firefox V56.0以下版本能够兼容close-proxy-authentication V1.1。
(2)不同geckodriver(Firefox的webdriver程序)版本,支持的Firefox版本也不相同,具体支持哪些版本,在geckodriver的releases页面上有说明。
测试结果如下图所示。没有再弹出认证窗口,访问httpbin.org/ip直接回显了HTTP代理的IP: